Transformer, Bert, GPT, chatGPT, … 都是啥
Transformer及其变种
- 2017/06, Google, Transformer
- “Attention is all you need”
- 2018/10, Google, Bert
- “Pre-training of Deep Bidirectional Transformers for Language Understanding”
- bi-directional transformer, encoder
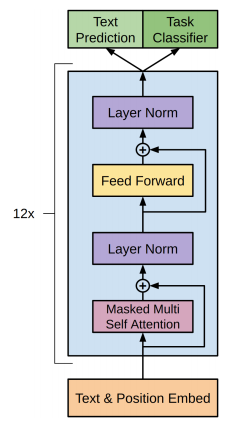
- 2018/06, OpenAI, GPT
- “Imporoving Language Understanding By Generative Pre-training”
- only decoder, supervised fine-tune but for one task
- 2019/02, OpenAI, GPT-2
- “Lanuage Models Are Unsupervised Multitask Learners”
- scale-up of GPT, no fine-tune but multi-task
- 1.5 billion parameters
- 2020/02, Google, T5
- 11 billion parameters
- 2020/05, OpenAI, GPT-3
- “Language Models Are Few-shot Learners”
- 175 billion parameters
- 2021/5, Google, LaMDA
- only decoder, 137 billion parameters
- 2022/1, OpenAI, InstructGPT
- 1.3 billion parameters
- 2022/5, Google, LaMDA-2
- 2022/11, OpenAI, ChatGPT
- 175 billion parameters
Model architecture
Transformer
- encoder, decoder
- attention
![]()
GPT
GPT codes