 MnasNet由谷歌的工程师发表,这里根据其论文简要描述一些细节。
MnasNet由谷歌的工程师发表,这里根据其论文简要描述一些细节。
MnasNet大体思路
AutoML通过使用算力来搜索网络结构的方式,给了人们很好的启发。谷歌工程师借鉴AutoML的思想,将增强学习应用于搜索适合手机的模型。
本质上,手机模型是在精度和速度之间的权衡。通过将速度设计进入增强学习的激励中,我们可以寻找到速度快,且精度还可以的模型结构,称为MnasNet1。
那么如何评估速度呢?
- FLOPS,即每秒浮点运算次数
- 直接运行模型
MnasNet采用了在手机上直接运行模型的方式来评估速度。
公式化描述问题
我们定义一些符号以便描述。
- \( m \) 是模型。
- \( ACC(m) \) 代表模型的精度。
- \( LAT(m) \) 代表模型的运算耗时。
- \( T \) 是一个预先设定的耗时上界。
通常的做法是最大化 \( ACC(m) \) ,同时要求 \( LAT(m) \leqslant T \) 。然而这并不是帕累托最优解(Pareto optimality)2。通过使用Weighted product model3方法,我们来寻找帕累托最优解。我们的优化目标由最大化 \( ACC(m) \),变为最大化:
$$ACC(m)\times \left [ \frac{LAT(m)}{T} \right ]^{w}$$
其中\( w \)是权重因子。
如何设置 \( \alpha \) 和 \( \beta \) 呢?这和我们的目标有关。如果我们希望牺牲1倍的速度来换取5%的精度的话,根据公式,\( 2^{-0.07}\approx 105\% \),所以 \( w \) 大概是-0.07左右。
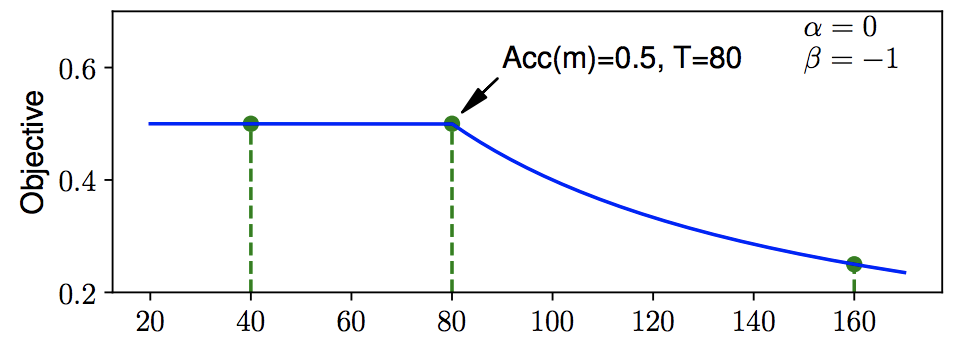 在上面的图中,我们在80ms以内追求精度,80ms以上则开始得到惩罚,从而促使尽可能在80ms以内。
在上面的图中,我们在80ms以内追求精度,80ms以上则开始得到惩罚,从而促使尽可能在80ms以内。
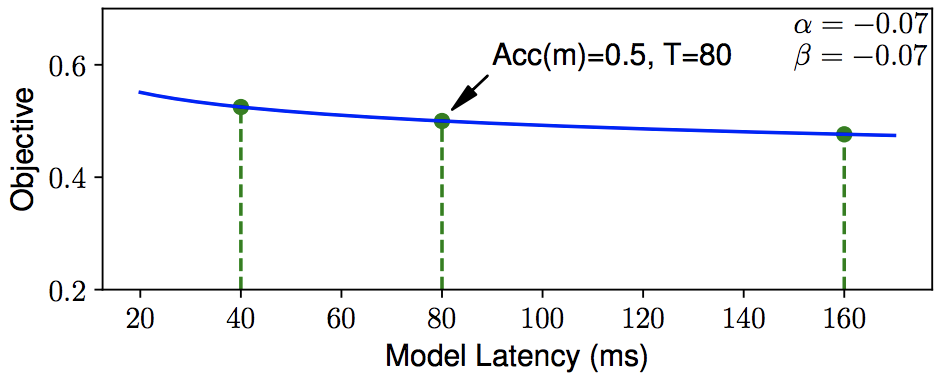 这幅图是MnasNet使用的配置,即固定为-0.07。如果结合强化学习动态调整这个参数,也许可以取得更好效果。
这幅图是MnasNet使用的配置,即固定为-0.07。如果结合强化学习动态调整这个参数,也许可以取得更好效果。
MnasNet搜索流程
MnasNet搜索系统结构
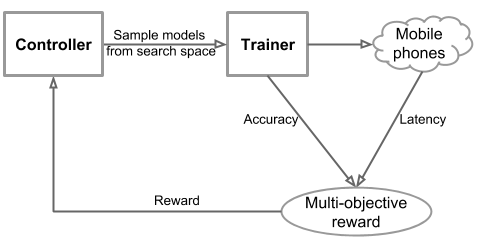
整个系统基于强化学习的思路,主要包含3大部分。
- Controller控制器,用于搜索和采样模型结构
- Trainer训练器,用于训练Controller送来的模型,得到精度值
- InferenceEngine推断器,用于在实际设备中进行运算,得到速度值
MnasNet使用了基于梯度的强化学习来进行搜索。我们也可以使用遗传算法来进行搜索。我们将解空间中每一个CNN模型映射为一系列token。这些token由强化学习中的一系列action得到。最大化强化学习的reward,即最大化\( ACC(m)\times \left [ \frac{LAT(m)}{T} \right ]^{w} \)。
- Controller基于RNN模型,来预测一系列token,从而得到一个CNN模型。
- Trainer根据训练数据来训练得到 \( ACC(m) \)。
- InferenceEngine在真机上评估得到 \( LAT(m) \)。
- 由前面的公式我们得到奖励。
- 根据奖励,依据基于梯度的强化学习算法,调整Controller的参数。
MnasNet搜索流程简化
为了在搜索灵活性和搜索空间大小之间取得适当的平衡,我们提出了一种新的分解层次搜索空间。
1.按block为单位搜索,允许不同block有适当差异
- AutoML的做法是对每一个layer进行搜索,搜索空间巨大。
- QC等论文4思路是搜索出一些复杂的cell,然后重复这些cell。
- MnasNet将网络划分为多个block
- 每个block又划分为多个layer,并在block内重复相同layer
- 不同block的layer可以不一样
2. 使用深度分离(depth-wise)卷积以及1x1卷积
和MobileNet5等思路一致,继续使用dpeth-wise卷积和1x1卷积来降低运算量,提高模型紧凑程度。如果输入深度(depth或channel)是M,输出深度是N。卷积大小为KxK。则总运算量下降为 \( H\times W\times M\times (K\times K + N) \)。
MobileNetV26的改进卷积也是搜索选择。
3. 根据经验预先定义大的结构和搜索选项
根据经验预先定义大的结构和搜索选项,以减少搜索空间。
- 定义了7个Block。
- 对于 \( Block_{i} \) ,有如下可搜索的设置
- 该Block里面的layer重复次数: \( N_{i} \)
- 该Block的输出tensor的深度:\( F_{i} \)
- SkipOp:
- max/average pooling
- identity residual skip
- 没有skip
- ConvOp:
- 常规卷积(conv)
- MobileNetV1的深度分离卷积(图中标为dconv)
- MobileNetV2的加强版深度分离卷积
- KernelSize:
- 3x3
- 5x5
由于Block内的layer是重复的,这也是每个layer的输出tensor的深度都是 \( F_{i} \)。所以
- \( F_{i} \),SkipOp,ConvOp, KernelSize这四个参数确定了一个layer。
- 再加上重复次数 \( N_{i} \),则确定了一个Block。
由此可见,搜索空间不是很大。
下图是搜索空间描述。
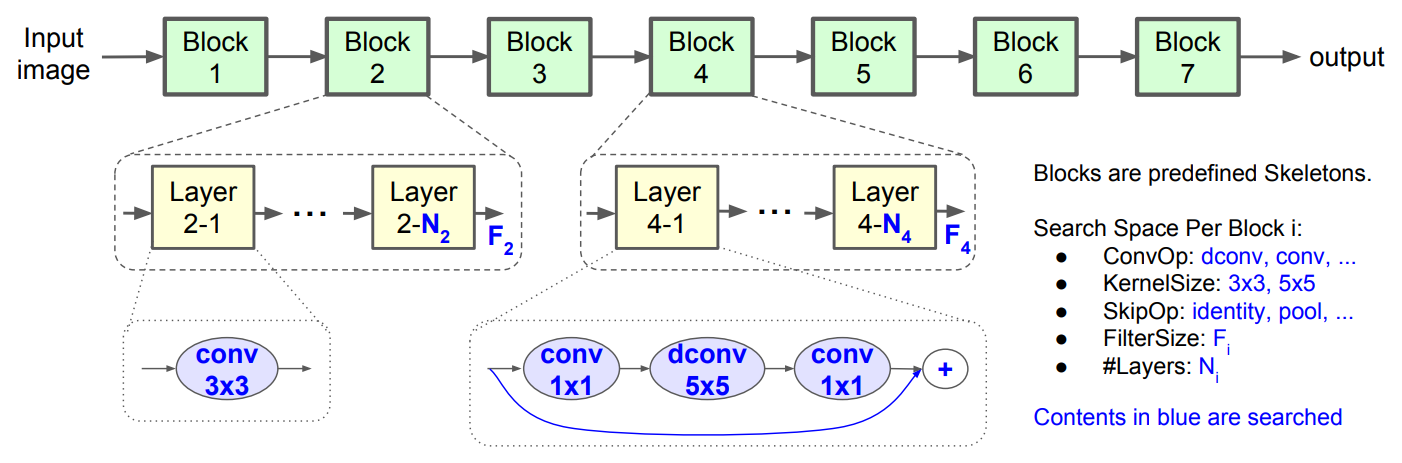
下图是一个baseline模型。

MnasNet效果
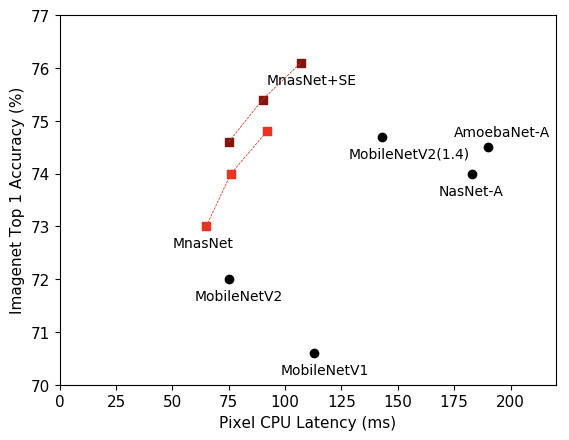
在获取同样的ImageNet Top-1精度的同时,
- MnasNet速度是MobileNetV2的1.5倍
- MnasNet速度是NASNet的2.4倍
- 图中的MnasNet+SE表示的是使用了squeeze-and-excitation7优化。
在COCO目标检测任务上,
- MnasNet的速度和精度都好于MobileNet
- 在达到和SSD3008模型同样精度的同时,速度提高了35倍。
MnasNet详细结构
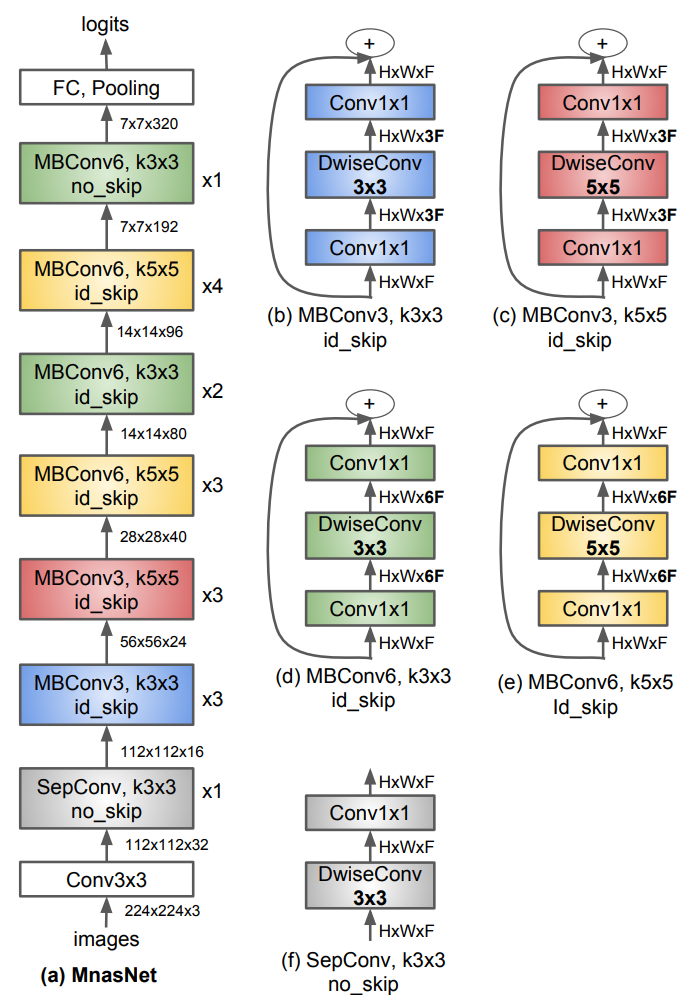
-
帕雷托最优是指资源分配的一种理想状态。给定固有的一群人和可分配的资源,如果从一种分配状态到另一种状态的变化中,在没有使任何人境况变坏的前提下,使得至少一个人变得更好,这就是帕雷托改善。帕雷托最优的状态就是不可能再有更多的帕雷托改善的状态;换句话说,不可能在不使任何其他人受损的情况下再改善某些人的境况。 ↩︎
-
Regularized Evolution for Image Classifier Architecture Search ↩︎