 今天是圣诞节,在家休假一周。忙了大半年总算可以喘口气了。年底了总要计划下未来,总结下过去,进行些人生思考,做些人生选择。
考虑到最近工作涉及到Bandit算法,忙里偷闲,整理出这篇文章。
今天是圣诞节,在家休假一周。忙了大半年总算可以喘口气了。年底了总要计划下未来,总结下过去,进行些人生思考,做些人生选择。
考虑到最近工作涉及到Bandit算法,忙里偷闲,整理出这篇文章。
老虎机模型,现在追本溯源基本认为是一个病理学家 Thompson 在 1933 年提出的。他当时觉得验证新药的医学的随机双盲实验有些残酷的地方, 对于被分到药效较差的新药的那一组病人并不公平。他想知道能否在实验中途就验证药物药效,从而避免给病人带来痛苦。因此他提出了一个序列决策模型。但是,实际使用还是有很多问题,比如中途效果不好评价。所以直到现在,美国 FDA 对在医学随机双盲实验中使用这种自适应调整的多臂老虎机方法, 仍然只是建议使用。
Bandit本意是土匪强盗暴徒。大部分暴徒总是爱进赌场。一个赌徒, 要去摇老虎机,走进赌场一看,一排老虎机,外表一模一样,但是每个老虎机吐钱的概率可不一样,他不知道每个老虎机吐钱的概率分布是什么, 那么想最大化收益该怎么整?怎么解决这个问题呢?去试一试,有策略地试,试一试是有成本的,试的次数越少越好,这些策略就是bandit算法。 bandit算法的一个前提是每个action,都立刻可以知道其reward,是一种特殊的增强学习。
Bandit算法的应用场景
- 推荐系统冷启动
有很多item(或category),user对各个item兴趣不一,对于新user,如何快速知道其对各个item的兴趣,以决定给这个user推荐什么item呢?
- 广告系统展示广告
有若干广告,如果每次都给用户暂时pCTR最高的广告,那么新广告何时才能被展示呢?总把头牌拿出去展示,会不会伤害整体利益呢?
- 实验验证
又想出了个新算法,或者界面新改版,需要进行A/B Test来进行数字化驱动的决策。有没有什么更快更好的办法呢?
Exploit和Explore,利用和探索
- Exploit:利用。找到一个方案了,就实施吧。
- Explore:探索。再探索探索,应该还有更好的。
Regret,遗憾
选择错了,那么就是遗憾。“哎,我当初怎么没选择那条路”。遗憾,regret,就是衡量bandit算法的loss function。 遗憾最小的选择,就是好选择。
$$ R_{T} = \sum_{i=1}^{T}(w_{opt}-w_{B(i)})= \sum_{i=1}^{T}w_{opt}-\sum_{i=1}^{T}w_{B(i)} $$
这个公式说明,我们试 T 次,第 i 次选择 B(i) 并得到一个回报 reward,即 \(w_{B(i)}\)。每次选择和最佳选择的回报之差就是遗憾, 积累多次的总遗憾就代表了这个选择策略的优劣,遗憾越小越好。
Context-free Bandit
Context-free Bandit的一个特点是reward是根据action来的,和环境的state无关。
与之对应的,如果reward和action以及state都有关系,则是Contextual Bandit。典型的案例比如:用户浏览财经频道点击汽车广告的概率,和用户在汽车频道点击同一汽车广告的概率很可能有很大差异。这需要考虑用户,时间等各种contexual信息。
随机选择
每次都随机选择一个。彻底瞎试。本质上是一直在Explore。
贪婪选择
先试几次,对每个老虎机求reward平均值,然后选均值最大的那个老虎机。可以想象,在先试几次阶段,它就是随机选择算法。 之后会一直贪婪地选择其中的一个老虎机。大部分人做决定,本质上就是这个策略。先Explore一段时间,然后一直Exploit。
Epsilon-Greedy算法
Epsilon,即第五号希腊字母ε。可以想像,一般greedy算法都简单有效。
- 选一个(0,1)之间较小的数epsilon。
- 每次以概率epsilon(产生一个[0,1]之间的随机数。
- 如果随机数比 epsilon 小,则所有臂中随机选一个;否则,采用greedy策略选择截止当前平均收益最大的那个。
不难理解
- epsilon越小,则越难随机选择,即越容易采用当前最佳策略,即Exploit。
- epsilon越大,则越容易进行随机选择,进而探索更多可能性,即Explore。
本质上,这个算法以一定概率结合了随机选择和贪婪选择,兼顾了Exploit和Explore。 你可能很容易想到,Expore阶段和Exploit阶段割裂的太明显了。能否长期将Expore阶段和Exploit阶段融合在一起呢?请看下面的算法。
Thompson Sampling算法
Thompson Sampling算法的实现比较简单,效果和下面的Upper Confidence Bound算法相当。
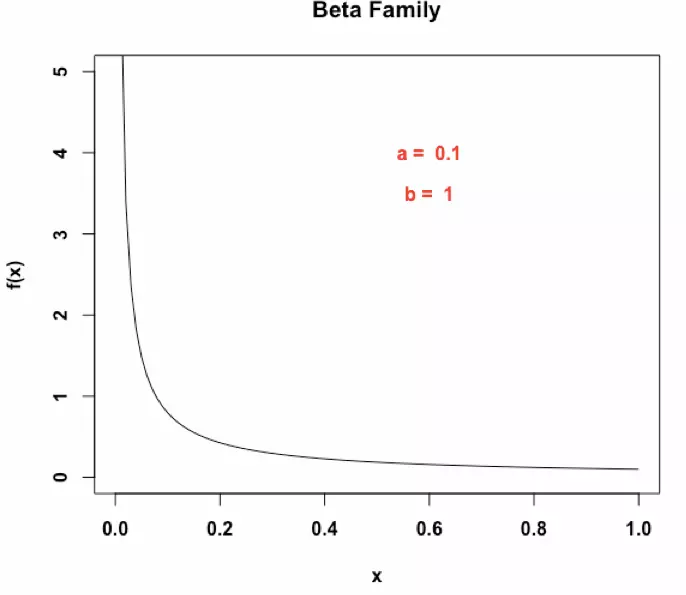
Beta分布
请先自行学习beta分布。马同学(matongxue314)的回答很好理解。
- beta分布可以看作一个概率的概率分布
- 先验概率 + 实验数据 = 后验概率。对于二项分布,先验概率和后验概率都是beta分布,是共轭先验。
- beta分布表达能力很强,见下图。
基于Beta分布的Thompson Sampling算法
- 假设每个老虎机产生收益的概率为 p 。
- 我们通过不断地实验,来估计出一个置信度较高的概率 p 的概率分布,即beta分布。
那么,如何去估计这个概率 p 的概率分布呢?
- 假设概率 p 的概率分布符合 beta(win, lose)分布,它有两个参数 win, lose。这个假设的前提是不赢就输(二项)。
- 每次实验,有收益1,则该老虎机的 win 增加 1,否则 lose 增加 1。
- 每次选择老虎机时,用每个老虎机的 beta 分布来产生一个随机数,选择随机数最大的那个老虎机。
Python代码如下:
choice = numpy.argmax(
pymc.rbeta(
1 + self.wins,
1 + self.trials - self.wins))
Upper Confidence Bound算法
Thompson Sampling算法从概率的概率分布角度,进行Expore+Exploit。Upper Confidence Bound(置信区间上届)算法则是从方差角度进行Expore+Exploit。
$$ \bar{x_{j}}(t)+\sqrt{\frac{2lnt}{T_{j,t}}} $$
其中 \( \bar{x_{j}}(t) \) 表示第j个老虎机到目前为止的收益均值。根号部分的分母T是这个老虎机被试的次数,t是目前总的试验次数。
朴素的理解是我们需要考虑两个角度
- 这台老虎机的收益均值越大越好。起Exploit作用
- 这台老虎机达到这一收益均值,被试的次数越小越好(方差小,均值高)。只试了几次就能高收益。应该优先被Expore一下让其被多试几次。
Upper Confidence Bound的代码实现比Thompson Sampling算法还要简单,不需要考虑beta分布的随机数生成问题。
各算法性能比较

Contextual Bandit
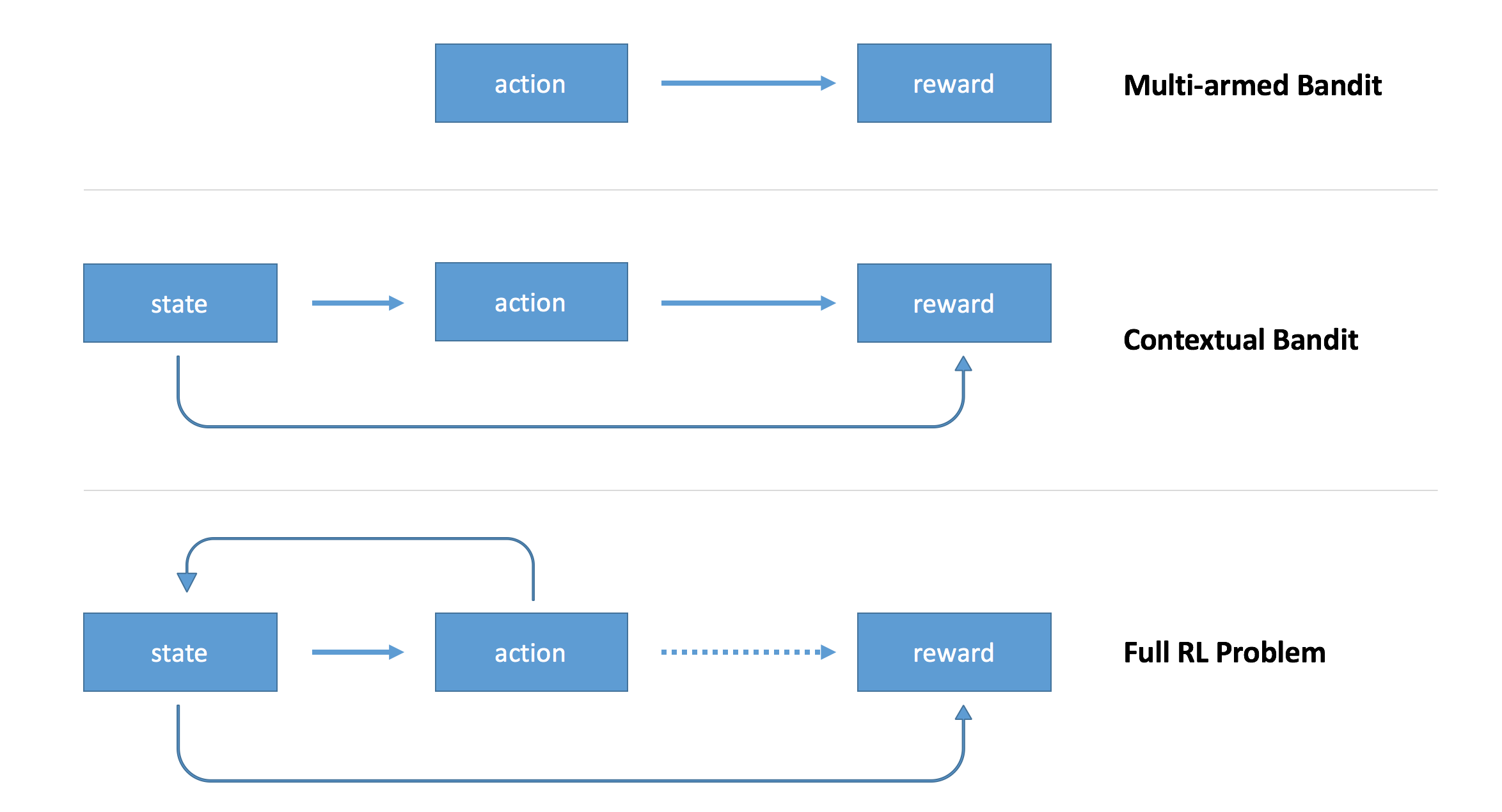
Context-free Bandit只考虑了action所产生的reward,但并没有考虑那只多臂大章鱼的特征信息。在推荐系统中,我们几乎不可能用Context-free Bandit。通常我们要考虑user特征,item特征,时间天气等各种特征,即:用附加信息刻画决策过程
LinUCB算法
Lihong Li(李力鸿)是这篇文章的主力,这一成果最早用于雅虎的新闻推荐,目前Lihong先生就职于Google,担任研究科学家,他的个人网站在这里。
LinUCB算法和其他Bandit算法一样都可以算作Online Learning算法。
参考
- Simple Reinforcement Learning with Tensorflow
- LinUCB
- Vowpal Wabbit - fast online learning code 发起于Yahoo,后被带到微软,用Spark的也许会考虑吧。
- TF-Agents 推荐。